# python server
async def price_push():
while True:
await asyncio.sleep(1)
price = random_price_generator()
await asyncio.wait([ws.send(str(price)) for ws in clients])
Data 영역 : 전역변수/정적 변수를 저장하는 공간. 프로그램 시작과 함께 할당되며, 프로그램이 종료되면 소멸
Stack 영역 : 지역 변수/매개변수를 저장하는 공간. 함수의 호출과 함께 할당되며, 함수의 호출이 완료되면 소멸
Heap 영역 : 사용자의 동적 할당으로 생성되는 공간. 사용자의 공간의 크기를 직접 관리할 수 있다. 메소드 호출이 끝나도 소멸되지 않는다.
Heap 영역의 크기 : 프로그램이 실행되는 도중인 런타임에 사용자가 직접 결정 ->동적 할당 Data 영역과 Stack 영역의 메모리 크기 : 컴파일 타임에 미리 결정 ->정적 할당
고정적으로 메모리를 할당받는 것 보다,
런타임에 메모리를 할당받는 '동적할당'을 통해 'Heap 영역'을 사용하는 것이 더 효율적!
def f2(x):
x = x + 1
return x
def f1(x):
x = x * 2
y = f2(x)
return y
y = 5
z = f1(y)
Heap vs Stack 비교
Stack영역이 클수록 Heap의 영역은 작아진다. 반면에 Heap영역이 클수록 Stack영역이 작아진다.
Stack
이미 할당되어 있는 공간을 사용.
메모리의 높은 주소에서 낮은 주소의 방향으로 할당된다.
한계가 있어 초과하게 삽입할 수 없다. -> 유연성이 낮음
Heap
사용자가 할당해서 사용하는 공간
메모리의 낮은 주소에서 높은 주소의 방향으로 할당된다.
-> Stack의 속도가 훨씬 빠르다. (하지만, stack은 공간이 매우 적기 때문에 모든 응용에서 stack을 사용할 수는 없다.)
JAVA와 Python의 메모리 할당 방식 차이점
Java : static method는Data 영역에 저장된다. Python : static method든 class method든 자동으로모든 객체들이 heap영역에 저장된다. -> 내부에서 효율적으로 메모리를 쓸수 있도록 자동적으로 동적할당 해주기 때문에, 사용자가 직접 메모리를 관리할 필요가 없다.
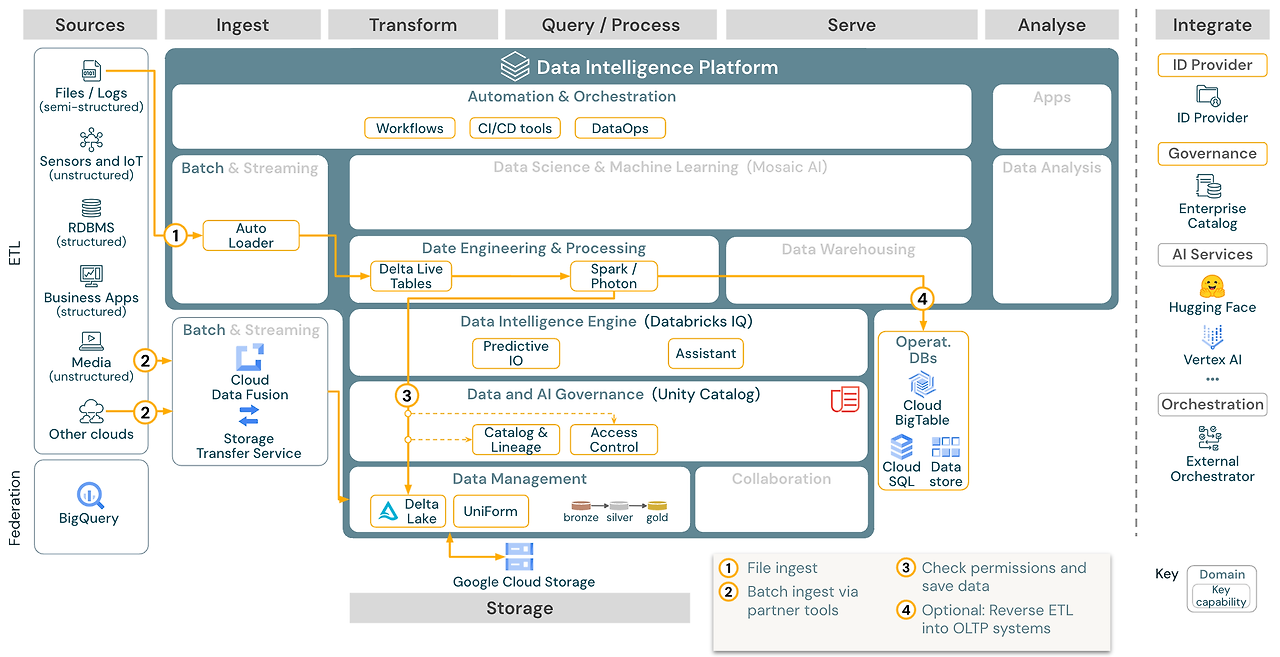
Databricks Lakehouse는 GCP 기반의데이터 통합 분석 플랫폼 Databricks 자체 엔진 + GCP 네이티브 서비스 + 파트너 솔루션 조합으로 구성되어 있고, Batch/Streaming/ML/BI/CDC/Federation 등 다양한 워크로드를 처리할 수 있도록 설계되어 있음.
1. Source
정형 / 반정형 / 비정형 데이터를 모두 수용
유형
예시
정형 데이터
RDBMS, Business Applications
반정형 데이터
JSON, CSV 등 (Logs, Files)
비정형 데이터
미디어, IoT, 센서
외부 데이터
타 클라우드, BigQuery (Federation)
*Federation: ETL 없이 SQL DB를 Databricks SQL에서 직접 쿼리 가능 (Unity Catalog에 매핑)
2. Ingest (데이터 수집)
유형
GCP
서비스설명
Batch
Cloud Data Fusion, Storage Transfer
- Cloud Storage로 데이터를 이동 - Cloud Storage로 전달된 파일 → Auto Loader로 읽음
Streaming
Kafka, Pub/Sub, Datastream
실시간 이벤트 데이터 처리
Databricks
Auto Loader, Structured Streaming
파일 변화 감지, Kafka/IoT 수신 등
3. Storage (데이터 저장)
Cloud Storage (Object Storage) 기반으로 저장하며, Databricks는 이를 Delta Lake 포맷으로 관리하여 Medallion Architecture (Bronze → Silver → Gold) 형태로 운영
4. Transform / Query & Process (변환/처리)
컴포넌트
설명
Apache Spark / Photon
고속 병렬 처리 엔진
DLT (Delta Live Tables)
선언형 방식의 안정적 ETL 파이프라인
Databricks SQL
SQL 기반 쿼리 및 데이터 웨어하우스
ML/AI
AutoML, Feature Engineering, MLflow 관리
Mosaic AI
생성형 AI 통합 (LLM 포함)
5. Serve (서빙)
대상
도구 / 기능
BI/DWH
Databricks SQL, Serverless SQL Warehouse
ML 모델
Model Serving (MLflow 기반), Mosaic AI Gateway
외부 시스템
Operational DB (예: Cloud SQL 등)으로 결과 Export
6. Analysis (분석)
대상
도구
BI 시각화
Looker, Tableau, Genie (Databricks Dashboards)
Custom App
Operational DB에 있는 골든 테이블을 활용
SQL Dev
Databricks SQL Editor (쿼리, 대시보드 지원)
7. Integrate (통합)
범주
내용
인증/보안
ID Provider 통합 (SSO 등)
AI 서비스
OpenAI, HuggingFace, LangChain 연결
오케스트레이션
Airflow, Cloud Composer, REST API
Governance
Unity Catalog (통합 권한, 계보 추적, 데이터/모델 거버넌스)
데이터 공유
Delta Sharing, Databricks Marketplace (공식 교환소)
공통 기능 (전 영역 공통)
Databricks Lakehouse 플랫폼 내에서 모든 워크로드에서 사용할 수 있는 기능들
기능
설명
Unity Catalog
통합 거버넌스: 테이블, 모델, 피처, 사용자 권한, 계보 추적 등
Databricks IQ
추천 기반 최적화 기능
Databricks Assistant
노트북/에디터에서 AI 코딩 보조
Observability
시스템 테이블 기반 모니터링/성능 추적
CI/CD & MLOps
DLT + Databricks Jobs + MLflow 로 자동화 파이프라인 운영
사용사례
Use case: Batch ETL
2. Use case: Streaming and change data capture (CDC)
Data Lakehouse는 Data Lake + Data warehouse 각 장점을 결합한 아키텍처로, 머신러닝(ML), 비즈니스 인텔리전스 (BI), 데이터 엔지니어링을 위한 통합 플랫폼을 제공
Data Lakehouse
데이터 레이크하우스는 두 시스템의 장점을 결합한 하이브리드 아키텍처
데이터 웨어하우스: 구조화된 데이터, 빠른 분석, BI에 최적화
데이터 레이크: 다양한 포맷과 형태의 데이터를 저장, 머신러닝(ML)에 적합
데이터 레이크하우스는 데이터를 계층적으로 정제하고 저장하면서, 이를 다양한 워크로드 (BI, ML 등)에 동시에 사용할 수 있는 단일 데이터 소스를 제공. 이는 데이터 사일로를 줄이고, 중복 비용을 없애며, 최신 데이터를 기반으로 한 의사결정을 가능하게 함
Data Lakehouse architecture
Databricks는 데이터 레이크하우스 아키텍쳐는 다음과 같은 주요 요소로 구성
데이터 수집: 다양한 소스에서 데이터를 배치 또는 스트리밍 형식으로 수집. 수집된 데이터는 Delta Lake를 사용하여 검증된 테이블로 변환되며, 스키마 강제 규칙을 통해 데이터 품질이 유지
데이터 처리 및 큐레이션: 데이터를 전제하고 새로운 특성을 생성하여 머신러닝을 위한 준비를 함. 스키마 진화(Schema Evovlution) 기능을 통해 기존 파이프라인을 방해하지 않고 데이터를 변경할 수 있음
*스키마 진화(Schema Evolution) 기능이란? 데이터 저장 구조(스키마)가 변경되더라도 기존 데이터나 시스템과의 호환성을 유지하면서 새로운 데이터를 처리할 수 있게 해주는 기능
데이터 제공: 정제된 데이터를 BI, 머신러닝 및 보고서 작성 등 다양한 용도로 최종 사용자에게 제공. 각 사용 사례에 맞게 최적화된 데이터 구조로 제공
Databricks에서의 Data Lakehouse 핵심 기술
Databricks는 Apache Spark 기반의 플랫폼으로, 다음과 같은 핵심 기술을 통해 Lakehouse를 구현
Delta Lake
데이터 레이크 위에 ACID 트랜잭션, 스키마 강제, 데이터 버전 관리 등의 기능을 더하여 데이터 안정성과 신뢰성을 높이는 스토리지 계층
Unity Catalog
조직 내 데이터 및 AI 자산에 대한 중앙 집중식이고 세밀한 거버넌스 솔루션을 제공하여 데이터 보안과 쥬정 준수를 강화
Data Lakehouse 활용
실시간 데이터 분석: 스트리밍 데이터를 즉시 처리하여 실시간 인사이트를 확보하고 신속한 의사 결정을 지원
데이터 통합 및 단일 정보 소스 구축: 모든 데이터를 하나의 시스템으로 통합하여 데이터 사일로를 제거하고, 조직 전체의 일관된 데이터 뷰를 제공
유연한 스키마 관리: 비즈니스 변화에 따라 데이터 스키마를 자유롭게 변경하여 데이터 파이프라인의 유연성과 적응성을 높임
고성능 데이터 변환: Apache Spark와 Delta Lake의 강력한 성능을 활용하여 대규모 데이터 변환 작업을 빠르고 안정적으로 처리
통합된 분석 및 보고: 데이터 웨어하우스 수준의 성능으로 복잡한 분석 쿼리를 실행하고, BI 및 보고 기능을 효율적으로 지원
AI 및 머신러닝 역량 강화: 모든 데이터에 고급 분석 기술과 머신러닝 모델을 적용하여 데이터의 가치를 극대화하고 새로운 인사이트 발굴
데이터 거버넌스 및 보안 강화: 중앙 집중식 거버넌스 시스템을 통해 데이터 접근 권한을 효과적으로 관리하고 감사를 수행하여 데이터 보안 및 규제 준수를 용이하게 함
데이터 협업 및 공유 증진: 큐레이션된 데이터셋과 분석 결과를 팀 간에 쉽게 공유하여 데이터 기반 협업을 활성화
운영 효율성 증대: 머신러닝 기반 운영 분석을 통해 데이터 품질, 모델 성능 변화 등을 실시간으로 모니터링하고 예측하여 시스템 운영 효율성을 높임
Databricks Lakehouse의 작동 원리
수집(Ingestion)→처리, 큐레이션 및 통합(Processing, Curation, and Integration)→제공(Serving)의 3단계로 나누어 관리
수집 (Ingestion): 다양한 소스의 원시 데이터를 Delta Lake 형식으로 안전하게 저장하고, 스키마 강제 및 Unity Catalog를 통한 거버넌스를 적용
처리, 큐레이션 및 통합 (Processing, Curation, and Integration): 데이터 과학자 및 엔지니어가 데이터를 정제, 변환, 통합하여 분석 활용에 적합한 형태로 만듦. Delta Lake의 스키마 진화 기능을 통해 다운스트림 작업에 영향을 최소화하며 스키마 변경이 가능
제공 (Serving): 최종 사용자의 다양한 요구 사항에 맞춰 최적화된 형태로 데이터를 제공. Unity Catalog를 통해 데이터 계보 추적이 가능하며, 통합된 거버넌스 모델을 통해 데이터 접근 및 사용을 통제
Lakehouse의 계층 구조(Medallion Architecture)
아래와 같은 계층적 데이터 설계를 따름
Bronze Layer - 데이터 수집
batch/streaming 방식으로 다양한 소스에서 원시(Raw) 데이터를 수집
Delta Lake로 변환하면서 스키마 유효성 검사 수행
Silber Layer - 데이터 정제
결측값 처리, 포맷 정리, 데이터 클렌징 등 데이터 품질 개선
분석/ML에 적합한 포맷으로 변환
Gold Layer - 데이터 서빙
비즈니스 사용자를 위한 최종 분석 테이블 제공
BI 리포트, 대시보드, ML 모델링에 바로 활용 가능
주요 기능 정리
기능
설명
실시간 데이터 처리
스트리밍 데이터 실시간 분석
통합 데이터 저장
모든 데이터를 하나의 시스템에 저장
스키마 진화
데이터 구조 변경을 유연하게 반영
데이터 버전 관리 및 계보
변경 이력 및 계보 추적 가능
머신러닝 지원
ML 모델 학습/예측에 최적화된 구조
데이터 거버넌스
통합된 보안 및 접근 제어 체계
데이터 공유
팀 간 데이터 세트 및 리포트 공유
운영 데이터 분석
모델 품질, 데이터 품질 모니터링 가능
레이크하우스 vs 데이터 레이크 vs 데이터 웨어하우스
특징
데이터 레이크 (Data Lake)
데이터 웨어하우스 (Data Warehouse)
데이터 레이크하우스 (Data Lakehouse)
데이터 형식
모든 형식 (정형, 비정형, 반정형)
정형 데이터
모든 형식 (Delta Lake를 통해 구조화 및 관리)
스키마
스키마-온-리드 (Schema-on-Read)
스키마-온-라이트 (Schema-on-Write)
스키마-온-리드 및 스키마-온-라이트 지원 (Delta Lake의 스키마 강제)
데이터 처리
데이터 과학, 머신러닝에 주로 사용
BI, 보고, 분석에 최적화
데이터 과학, 머신러닝, BI, 보고 등 다양한 워크로드 지원
성능
대규모 데이터 저장 및 처리에는 효율적이나, 복잡한 쿼리 성능 저하 가능성
복잡한 분석 쿼리에 최적화, 빠른 응답 시간
최적화된 메타데이터 레이어 및 데이터 레이아웃으로 높은 쿼리 성능 및 안정성
거버넌스
상대적으로 낮은 거버넌스 및 보안
엄격한 거버넌스 및 보안
통합된 거버넌스 및 보안 (Unity Catalog 활용)
ACID 트랜잭션
지원하지 않음
지원
Delta Lake를 통해 지원
정리
Lakehouse는 데이터 레이크의 확장성과 유연성, 그리고 데이터 웨어하우스의 안정성과 쿼리 성능을 결합한 차세대 데이터 아키텍처 다양한 형식의 데이터를 저렴하게 저장하면서, 정제된 데이터로 고속 분석과 머신러닝 작업가지 가능하게 해줌 하나의 플랫폼에서 실시간 처리, 데이터 거버넌스, 분석 및 AI 워크로드까지 모두 다룰 수 있어, 데이터 사일로를 줄이고 조직 전체가 하나의신뢰할 수 있는 데이터기반으로 협업할 수 있게 도와줌
*데이터 사일로(Data Silo) 조직 내에서 데이터가 부서나 팀 단위로 고립되어 서로 공유되지 않는 상태